Multimodal AI is an important step towards AGI.
“Multimodal AI is essential for building intelligent systems that understand the world as humans do, and it is a crucial step toward artificial general intelligence.” – Yann LeCun
Fusing Text and Images
CLIP is one of the first large-scale models to fuse text and image representations effectively, demonstrating strong zero-shot generalization across vision tasks. Multimodal learning—combining different types of data—may be a crucial step toward more general forms of artificial intelligence, possibly even AGI.
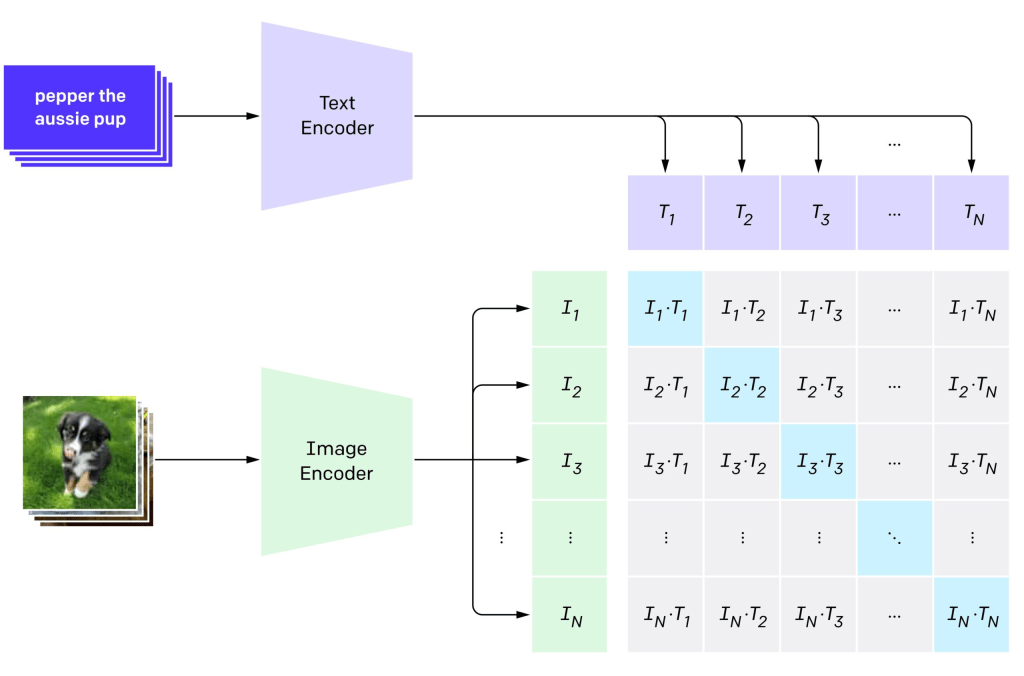

Image taken from:https://www.appypiedesign.ai/api/image-to-text/llava-1.5-api
Vision-Language Model: LLaVA
Read about the architecture of LLaVA and a case study of fine tuning LLaVA for a downstream task.
Subscribe for Deep Learning Insights
Get updates on the latest breakthroughs and tutorials in deep learning.
